Boris Eldagsen über KI in der Fotografie
Der bekannte Fotokünstler und Stratege für digitales Marketing Boris Eldagsen schätzt seit mehr als 20 Jahren den experimentellen Zugang zu Fotografie und beschäftigt sich insbesondere mit digitalen, zukunftsweisenden Möglichkeiten in der Branche. Derzeit steigt er tief ein ins Thema Fotografie und Künstliche Intelligenz und nimmt uns Bildbeschaffer mit ins Eingemachte. Das Interview für die Bildbeschaffer führte Jana Kühle.
Boris, sehr viele etablierte Fotografinnen und Fotografen reagieren mit Abwehr, sobald das Thema Künstliche Intelligenz aufkommt. Warum ist es bei dir anders?
Ich bin von Natur aus neugierig auf alles, was mit Kreativität zu tun hat. Auch das Thema KI-generierte Bilder betrachte ich aus einem kreativen Blickwinkel. Wir haben es mit einer neuen Technik zu tun, die in gewisser Weise so disruptiv ist, wie es das Internet und später auch die Smartphones waren. Ich denke heute wie damals: Wow, da tun sich unglaublich viele Türen auf! Rechtlich gibt es noch vieles zu klären, aber viele stürmen schon voran, ganz nach dem Motto: Lass uns einfach machen! Das wird natürlich sehr viele Konsequenzen haben …
Du testest derzeit verschiedene KI-Anwendungen. Was fällt dir dabei besonders auf?
Die Technik entwickelt sich so rasant, dass alles, was man darüber liest und hört, schon nach wenigen Wochen wieder veraltet ist. Seit dem Sommer beschäftige ich mich nahezu täglich mit KI, um auf dem neuesten Stand zu bleiben. Am Anfang habe ich das Programm Midjourney getestet. Als es mir zu illustrationslastig wurde, bin ich als Beta-tester auf DALL-E umgeschwenkt.
Es handelt sich dabei um Programme, die mithilfe von Texteingaben ganze Bilder kreieren. Man wird den Eindruck nicht los, dass das, was in der technischen Entwicklung früher drei Jahre waren, heute in drei Wochen passiert.
So ist es. Die Konkurrenz hat sich mittlerweile dahingehend entwickelt, dass es nicht mehr nur die Big Player sind, die ihr Insider-Wissen für sich behalten. So war DALL-E zwar der Leader, aber nur mit Registrierung zu erreichen und sehr restriktiv. Dann kam Ende August als Open Source Stable Diffusion (ein Deep-Learning-Text-to-Image-Modell, Anm. d. Red.). Was sich seitdem tut, ist einfach irre.
Worin liegt der Unterschied zwischen den Anbietern, außer dass Stable Diffusion als Open Source für jeden zugänglich ist?
Während Dall-E smart, einfach und mit nur wenigen Optionen versehen ist, ist Stable Diffusion das Gegenteil davon. Wer sich einarbeitet, fühlt sich wie damals, als man mit dem Programm Photoshop von Null angefangen hat. Allein die Installation fühlt sich an, als müsse man Programmierer sein. Es ist das Gegenteil von nutzerfreundlich. Aber es gibt unglaublich viele kreative Möglichkeiten und es macht mir großen Spaß, damit zu experimentieren. Bei DALL-E habe ich die Restriktionen ausgereizt und Stichworte eingegeben, bis mein Account gesperrt wurde. Daraus ist die Arbeit VOMIT entstanden. Nach der Sperrung aber kam glücklicherweise Stable Diffusion und dort habe ich dann angefangen, mit Sprache zu experimentieren.
Inwiefern?
Ich habe zum Beispiel den Text so weit verschachtelt, dass sich Subjekt und Objekt nicht mehr einfach auflösen. Das heißt, ich verwirre die KI durch den Satzbau. Dann habe ich neue Worte erfunden und geschaut, was passiert. Ich habe bewusst Worte falsch geschrieben. Da kommen unglaubliche Mutationen heraus. Zu Beginn waren die ja ein großes Problem von Stable Diffusion, aber mittlerweile gibt es auch dafür schon Lösungen. Innerhalb von wenigen Wochen haben sie sich extrem weiterentwickelt. Und das ist erst der Anfang. Es kostet mich nichts, ich kann das Programm mit meinem eigenen Input trainieren und habe alle künstlerische Freiheit, damit zu arbeiten. Die wenigsten sehen es als ein Element in einem Workflow. Aber jetzt gilt es natürlich, zu erarbeiten, wie man diese Software am besten nutzt.
Nimm uns gern einmal mit in die Welt der Open-Source-Software. Wie haben wir uns das vorzustellen?
Gern. Ich kann anhand von Texeingaben (Prompts) zum Beispiel beschreiben, was zu sehen sein soll und auch im zweiten Schritt wieder ausschließen, was ich nicht sehen möchte. Ich kann mir Bilder im Stil eines bekannten Künstlers generieren lassen. Ich kann bestimmen, wie viele Schritte der Bildgenerierung (Sampling Steps) überhaupt gemacht werden. Natürlich kann ich auch die Größe des Bildes bestimmen. Es gibt sogar die Option, Gesichter zu restaurieren. Dann gibt es den sogenannten Hires-Fix, mit dem die Bilder hinterher noch mal gesäubert werden. Ich kann eingeben, wie viele Bilder auf einmal errechnet werden. Und ich kann einen sogenannten Seed einstellen. Wenn man auf verschiedene Plattformen wie Lexica.art gehen, wo andere ihre Prompts (die Textvorgaben für die Bildkreation, Anm. d. Red.) und Ergebnisse zeigen, dann haben diese Bilder immer eine Nummer, das ist die Nummer des Seeds. Das heißt, ich kann ein Bild einer anderen Person nehmen und das als Ausgangsmaterial für meine Arbeit nutzen.
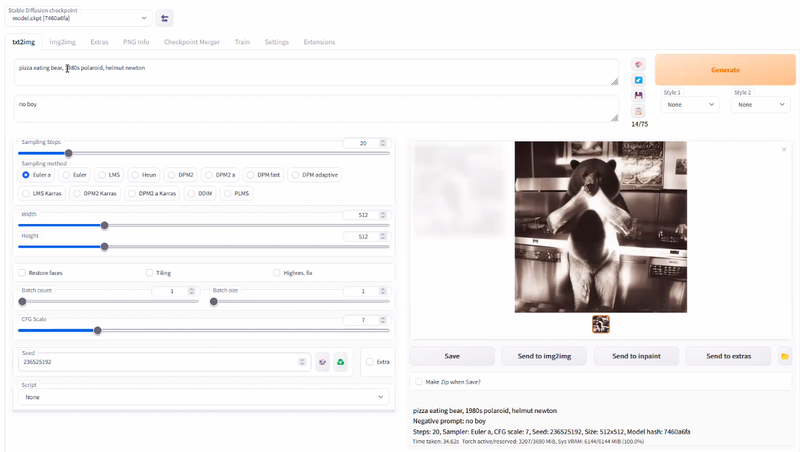
Das Ergebnis von Stable Diffusion, wenn man als sogenannten Text-Prompt „pizza eating bear, 1980s, polaroid, helmut newton“ eingibt. Die Küche, die im Hintergrund erscheint, ließe sich in Sekundenschnelle per Negativ-Befehl „kitchen“ durch einen beliebigen anderen Hintergund ersetzen.
Mit einem senkrechten Strich als Befehl kann ich zudem verschiedene Aspekte (z.B. Lichtverhältnisse, Perspektive, Filmwahl) als Variante berechnen lassen. Das gibt es bei DALL-E zum Beispiel nicht. Oder wenn mir eine Person ausgeworfen wird, deren Gesicht mir nicht gefällt, kann ich es wegradieren und neu errechnen lassen, während der Rest des Bildes bestehen bleibt. Oh, und ich sehe gerade, es gibt schon wieder eine neue Funktion, die es gestern noch nicht gab, „Extensions“.
Das sieht alles so professionell wie komplex aus.
Ich habe mir zwei Videos durchgeschaut, um überhaupt durchzusteigen. Das sind unglaublich viele Optionen, die zunächst ziemlich benutzerunfreundlich sind. Der Ottonormalverbraucher kann damit nichts anfangen. Aber irgendwann wird wohl auch eine Version bereitstehen, die leichter zu installieren und zu benutzen ist.
Ende Oktober gab es die Ankündigung von Shutterstock, mit DALL-E zusammen zu arbeiten.
Ich nehme an, DALL-E wird künftig auch mehr Optionen anbieten, ich kann mir aber nur schwer vorstellen, dass es mit Stable Diffusion mithalten kann.
Getty wiederum hat die Zusammenarbeit mit dem israelischen Anbierter Bria angekündigt. Warum sollte man überhaupt über Agenturen wie Getty oder Shutterstock gehen und Geld bezahlen, wenn es Stable Diffusion zum Selbermachen gibt?
Naja, da sind wir wieder bei der nicht sonderlich benutzerfreundlichen Oberfläche. Allein die Installation, die über Windows Command läuft – das ist viel zu kompliziert und komplex. Es wird einfach zu viel vorausgesetzt für den normalen Nutzer. Ich gehe davon aus, dass die meisten Plattformen sich einen Partner suchen. Es wird also immer mehr Anbieter von KI-generierten Bildern geben. Das, was Stable Diffusion als OpenSource entwickelt, ist aber natürlich radikal. Nichts hat ein Copyright, du kannst damit machen, was du willst. Das kann ein Unternehmen in der Form nicht bieten.
Wagen wir den Blick in die Glaskugel. Was bedeutet all das für Fotografinnen und Fotografen, für Fotoredaktionen, für die Beschaffung von Bildern?

Auch mithilfe von DALL-E2 lassen sich schon fotorealistische Bilder nur durch Texteingabe erzeugen (links das Original, rechts der KI-Nachbau von Boris Eldagsen).
Die Technik ist ja schon da. Ich habe mich selber schon hingesetzt und für den BFF (Bund Freischaffender Fotografen und Fotodesigner) eine Bildreihe kreiert, von der nur ein Bild das Original eines BFF-Fotografen war. Nicht immer lagen die Betrachter richtig mit ihrer Einschätzung, welches das Original ist. Die Financial Times hat Ende Oktober getestet, ob Menschen noch in der Lage sind, KI-generierte Bilder zu erkennen und von echten zu unterscheiden. 80 Prozent konnten den Unterschied nicht erkennen. Man kann also sehr viel Schabernack damit betreiben. Für mich ist das ein so disruptives Medium wie die Digitalisierung. Das Wort KI-sierung gibt es als solches als Wort noch nicht, aber sie wird in alle Bereiche eingreifen. Du kannst mit KI alles errechnen lassen. Und dann gibt es Berufe im Bereich der Pornografie. Bei Stable Diffusion kommen auch viele „NSFW“-Ergebnisse – not safe for work, zu deutsch: pornografischer Inhalt. Also KI-Bilder von Sexualität, die in Wirklichkeit gar nicht möglich ist, weil der menschliche Körper dazu gar nicht in der Lage wäre.
Wie ändert es die Arbeit eines Fotografen?
2019 hat man mir noch ein Bild gegeben und gesagt „Mach mir das mal in Grün“, das Budget betrug 1500 Euro. Jetzt kostet es für ein ähnliches Ergebnis mit KI nur noch 3 Cent. Die Agenturen arbeiten schon damit, sowohl in der Entwicklung als auch in der Umsetzung von Ideen. Alle Jobs, in denen es heißt „Mach mir das Gleiche in Grün“ müssen nicht mehr fotografiert werden. Mood-Bilder wie alte Leute auf einer Parkbank sind generierbar. Dafür wird es keine Fotografen mehr brauchen. Was bleibt, sind Dokumentationen oder aktuelle Berichterstattung, Promi-Hochzeiten, Events.
Willkommen in der Welt des auch gefährlichen Deep Fake.
Definitiv. Ich habe auch ein echtes Bild aus dem Kriegsgebiet in Butscha einfach mal in verschiedenen Variationen generiert. Man kann also in kurzer Zeit eine Alternative produzieren und es über Social Media verbreiten, ohne dass es als Deep Fake erkennbar ist. Diese Stufe der Manipulation ist keine Zukunftsmusik mehr. Ich gehe davon aus, dass die Fakten noch schwieriger sind zu wahren.
Also würdest du die These unterschreiben, dass das Vertrauen in visuelle Medien radikal verloren geht?
Das muss es. Wenn es das nicht tut, dann wird die Gesellschaft manipuliert.
Was durch die Rechtsprechung nicht in Zaum gehalten werden kann?
Die Rechtsprechung kommt zu spät. Erst recht, wenn ich eine Armee von Bots habe, die es für mich machen. Was will da die Rechtsprechung machen? Vor mehr als zehn Jahren habe ich mich schon mit Manipulation in Social Media beschäftigt – wenn man da tiefer einsteigt, blickt man in einen Abgrund. Früher gab es Klick-Farmen in Asien oder Afrika, heute sind es zusammengeschaltete Smartphones in China, die Plattformen bespielen können. Das Aufräumen der großen Social-Media-Anbieter ist immer ein Nachfegen. Sie hinken immer ein paar Schritte hinterher. Und die Art und Weise, wie man als Bot seine Spuren verdecken kann, öffnen ganz andere Probleme.
Leser nehmen Models ja häufig gar nicht wahr, selbst wenn sie auf zwei Plakaten für verschiedene Unternehmen an derselben Bushaltestelle hängen. Sie nehmen die Botschaft und die Bildstimmung auf, der Mensch selbst bleibt diffus. Diese Bilder lassen sich dann auch per KI generieren.
Ich habe mit KI-generierten Bildern ja immer wieder einen neuen Menschen, der nicht existiert. Somit gibt es auch das Problem nicht mehr, dass ein und derselbe Mensch bzw. dasselbe Model auf unterschiedlichen Werbeflächen immer wieder auftaucht. Der Wahrheitsgehalt von Symbolbildern in Werbung hat sowieso nicht existiert. Ich habe mal ein halbes Jahr für einen Werbefotografen assistiert, das fand ich sehr erhellend zum Thema Wahrheit. Alles war konstruiert. Ich sehe da im Digitalen keinen Unterschied. Das Entscheidende wird sein, dass man weiß, wie man die Tools benutzt. So wie auch Photoshop oder eine Kamera ein Tool ist, das man bedienen können muss. Wer einfach nur einen Befehl eingibt und sich mit dem Ergebnis zufriedengibt, der kratzt an der Oberfläche vom Thema Künstliche Intelligenz. Die Programme sind schon weiter als die meisten von uns denken.
Herzlichen Dank für das aufschlussreiche Gespräch.
Wer Boris Eldagsen live zum Thema Fotografie und Künstliche Intelligenz erleben möchte, dem sei sein Vortrag am 4. Dezember auf der DFA-Tagung in den Hamburger Deichtorhallen empfohlen. Der Vortrag wird auch live über www.facebook.com/deutschefotografischeakademie gestreamt und ist hinterher über www.youtube.com/@deutschefotografischeakademie abrufbar.
Autorin: jk
Wenn Sie möchten, einmal pro Monat als Magazin per Email.
Weitere News:
-
Live-Webinare - die nächsten Termine
Donnerstag, 16.07.2026 | Tipps & Tricks
So geht Content. So gehen Bildrechte. So geht der AI Act. So prompten Sie richtig - unsere Webinare im Juli 2026.
Weiterlesen... -
Der podKARST mit Hans Brorsen, valid.tech
Mittwoch, 15.07.2026 |
Das AI Office der EU-Kommission veröffentlicht Anfang kommender Woche neue Leitlinien. Wir diskutieren die praktischen Konsequenzen für die Arbeit mit Bildern und KI-Inhalten.
Weiterlesen... -
Kennzeichnungspflicht im AI Act: Wie grau wird’s?
Dienstag, 14.07.2026 |
Es geht um Chatbots, KI-Output in Bild und Text und auch um Biometrie: Was muss wo wie gekennzeichnet werden, ab wann. Und: muss überhaupt gekennzeichnet werden? Auch auf einem Plakat?
Ja, nein, vielleicht…
Weiterlesen... -
podKARST
Donnerstag, 02.07.2026 |
Seit zwei Jahren ist unser podKARST auf LinkedIn jeden Monat on Air. Hier die aktuellen Ausgaben.
Weiterlesen...